The Plan
When building smaller tools I have built many times before I usually just start and iterate for a while, but when starting an open ended project such as Lazerbunny I like to think through the high level components and architecture for a bit. This does not mean I am going full early 2000s architect mode, but I scribble down enough to remember in a month or two what I was planning to do and why. As promised in the first post I’ll walk you through the thought process of the initial design.
When looking at an architecture diagram always remember Mike Tyson’s quote: "Everybody has a plan until they get punched in the face". The same is true for software architecture. "Only a Sith deals in absolutes" - same goes for a bad architect. (Okay, enough with the quotes.) But there is some truth to both. The longer you work on a project the more nuances you will uncover you did not anticipate, or requirements will be added or change. The worst you can do is strictly stick to the plan that does not account for any of that. Or changing your architecture at every single point, which is usually an indicator it was not well thought out in the first place (or too strict).
So let me walk you through the thought process of what I am building for my fun little distraction.
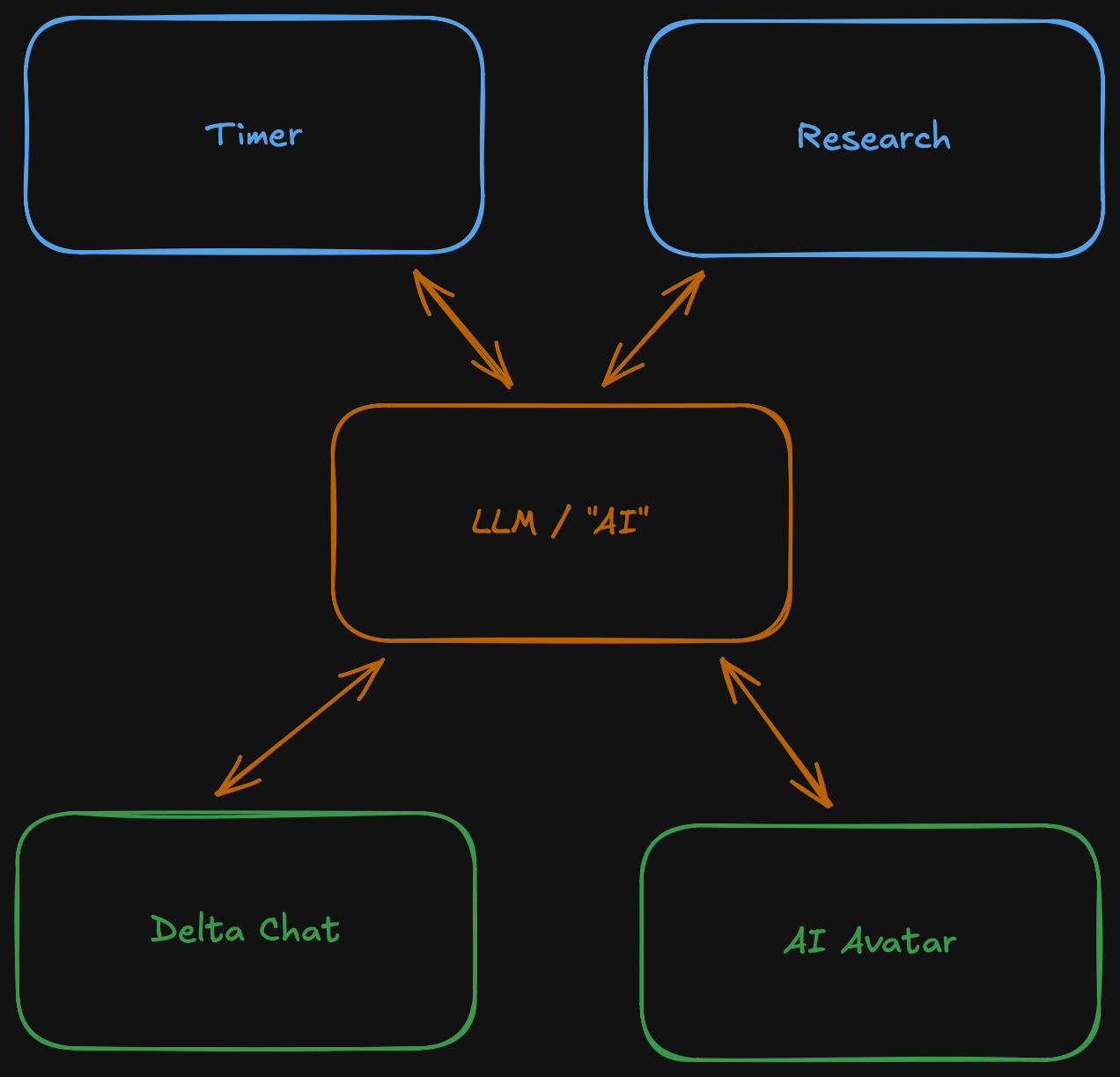
The idea is pretty simple. A central system running an LLM and kicking off tasks or operating agents, and two ways to interact with it. Either via chat or via the AI avatar. That seems like a decent scope to get started.
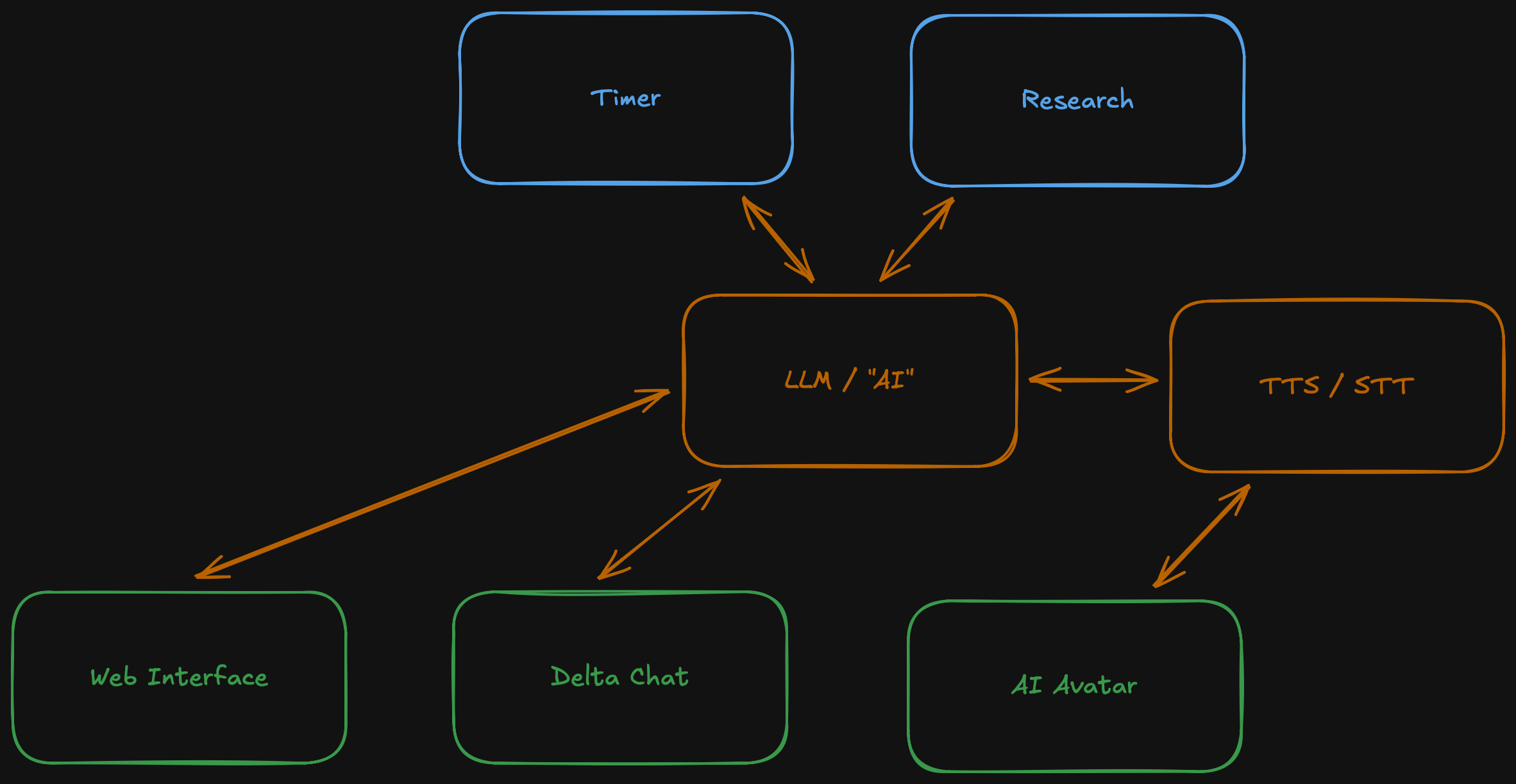
Now we obviously need text to speech and speech to text for our AI avatar, otherwise it would not be more interesting than looking at a static image or video without sound. Sometimes having a web interface for your AI might be really convenient. When in front of my computer I usually do not have any chats open and turning around talking to Endirillia while in a meeting might be a bit unprofessional.
The web interface should go beyond talking to the LLM. For example when the research agent is done, I want to be able to view the whole set of data including references. Maybe I want to stop a timer real quick. So each service needs a web interface as well.
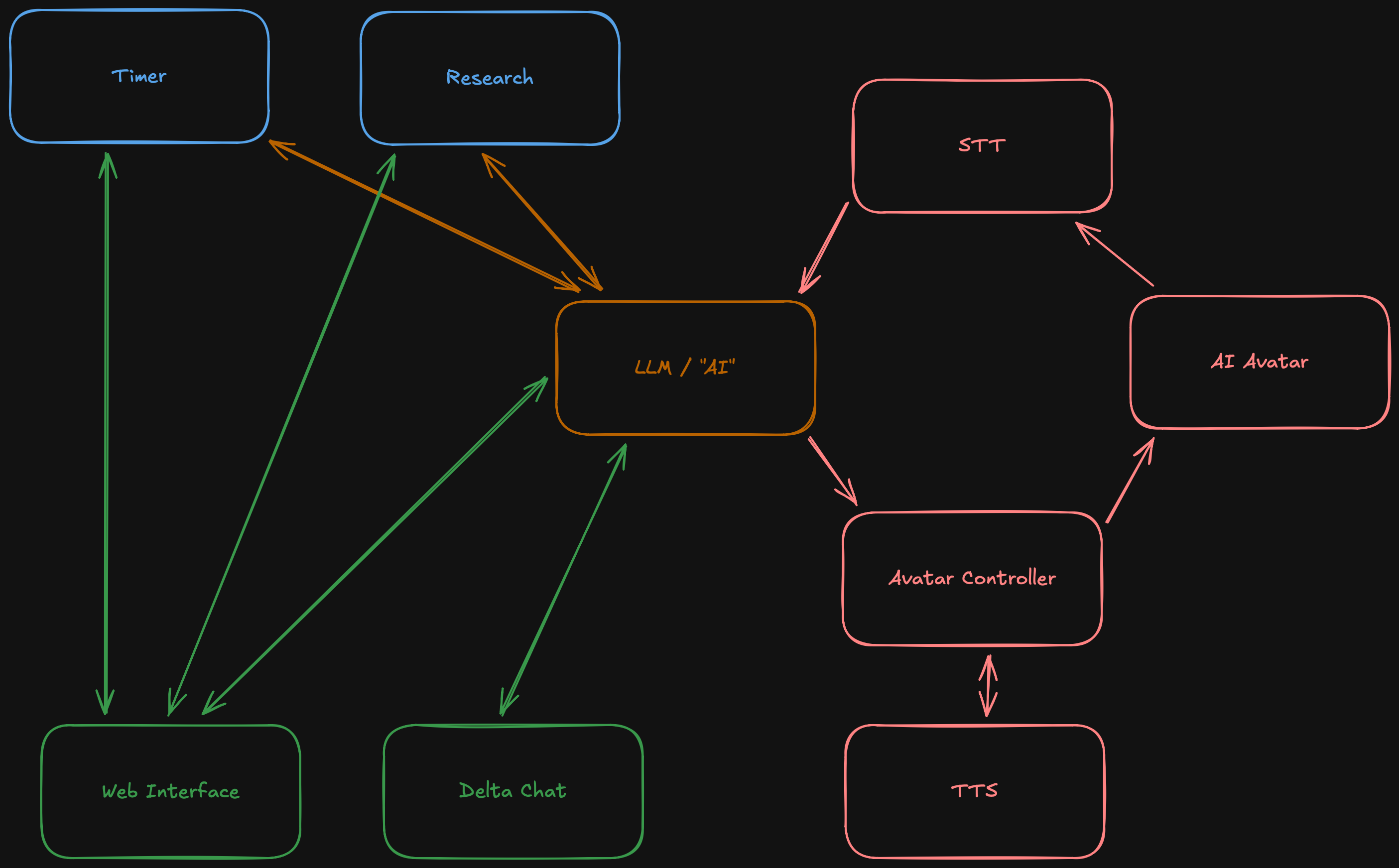
Now let us focus a bit on the avatar. As established before, we need speech to text and text to speech. This will likely be a small service running whisper or qwen3-asr. Qwen3 might be doing a bit better and it is not coming out of OpenAI which is another (minor) plus point for me. For text to speech I am planning to train a small model for qwen3-tts.
Beside that I also want a controller service to keep state of the avatar, so when I run it on two systems they are mostly in sync. It will also be easier to queue up any messages the avatar will "speak".
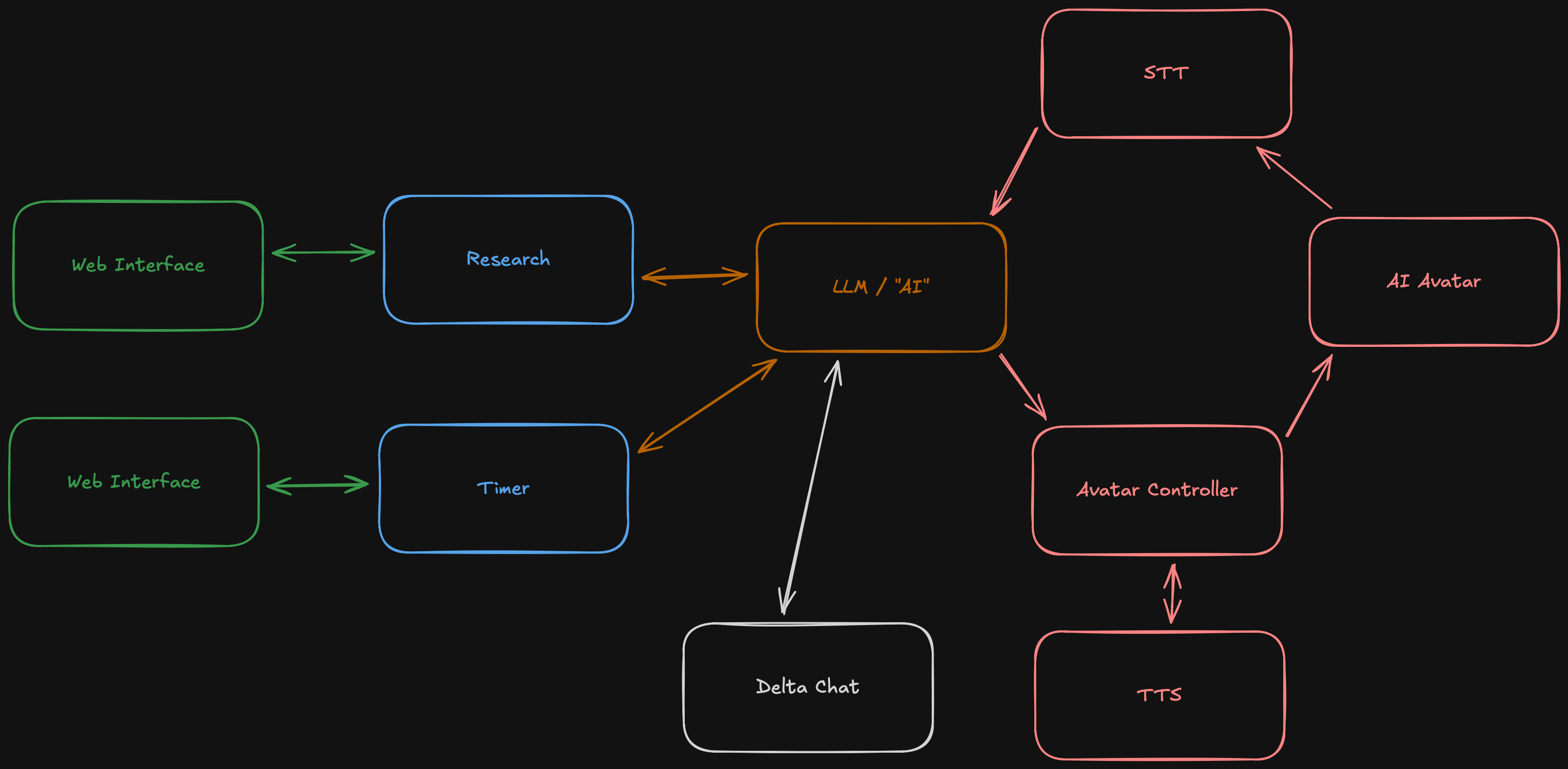
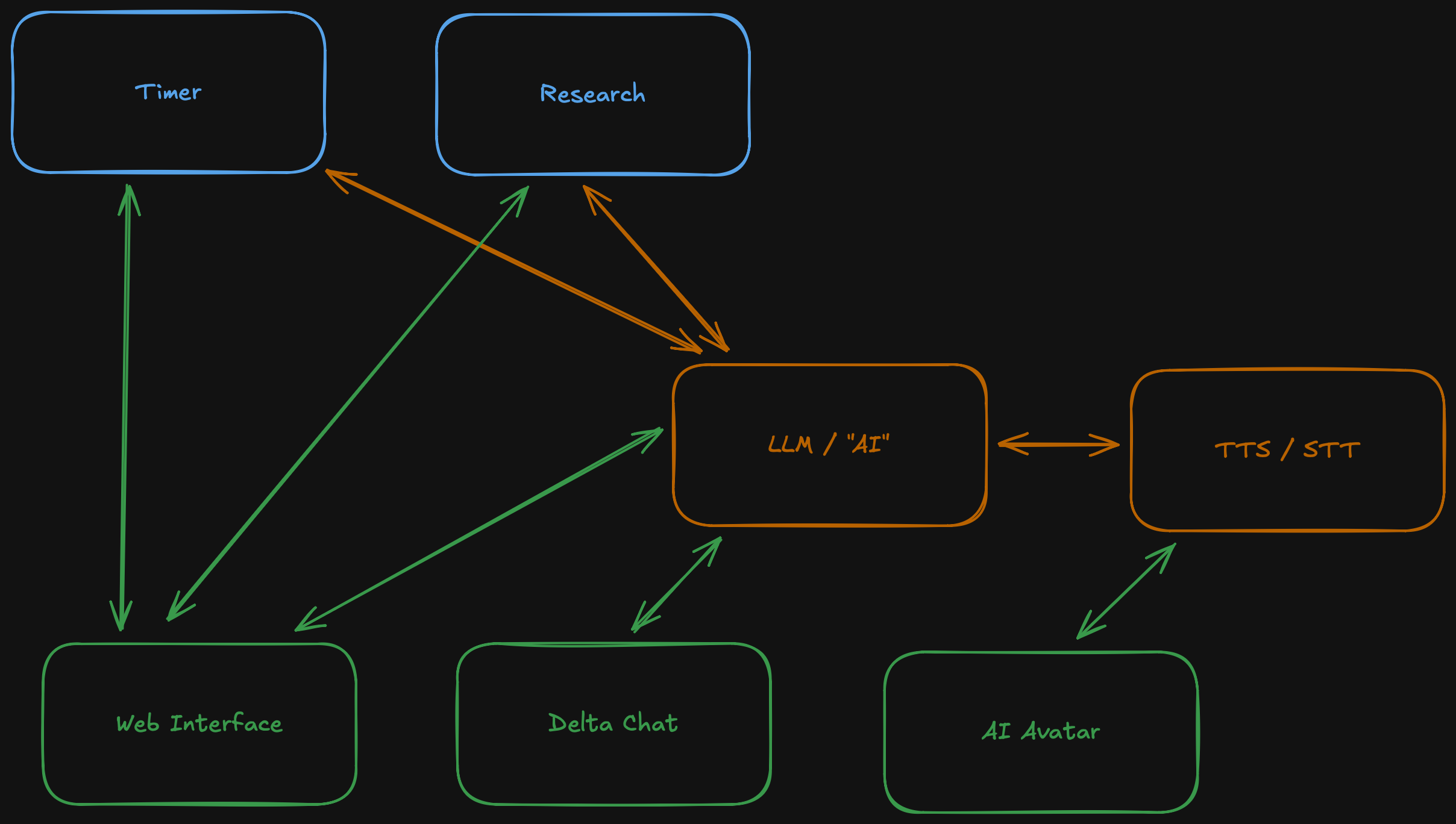
Back to the web interface. They are completely different for each service and they might need to provide context for the LLM to know if any instructions are a "new thread" or a follow up on an existing one. So let us break down the web interface into multiple web interfaces.
Delta chat changed its color as it will not adhere to the same principles and optional context as service specific web interfaces, but be more a general chat bot interface as you know it from most AI based services. Boring, I know.
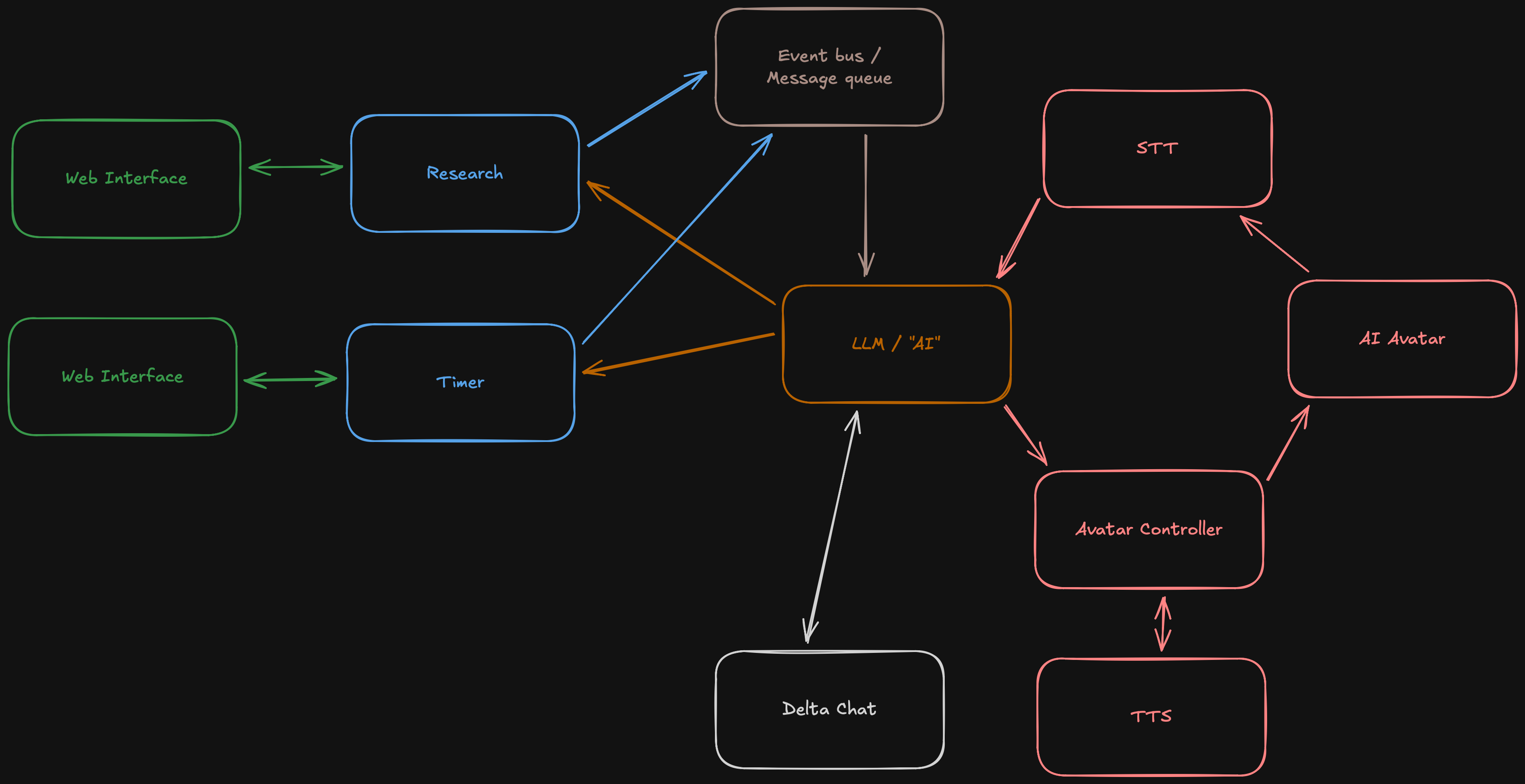
Now there will be long running tasks or other announcements such as a timer finishing. Most of the time I do not just want to process them in order but also aggregate them. Your assistant does not walk into your office and tells you.
"The timer for your pizza just finished."
"Research on text to speech models showed some promising results."
"Batteries in the server rooms smoke detector need to be replaced."
You would like to get a more concise update, at least I would hope so.
"Research on text to speech is done, batteries in the server rooms smoke detector need to be replaced and your pizza is ready."
Sounds much nicer if you ask me and once you run it through a TTS model it becomes even clearer that you want to aggregate messages that would otherwise play in rapid succession.
To make this work we add an event bus or a message queue to the mix which can be pooled every 5 or 10 seconds, or push all messages every few seconds. The trick will be finding a window that is not too long so your pizza gets burned and not too short so you have 2 second pauses between messages.
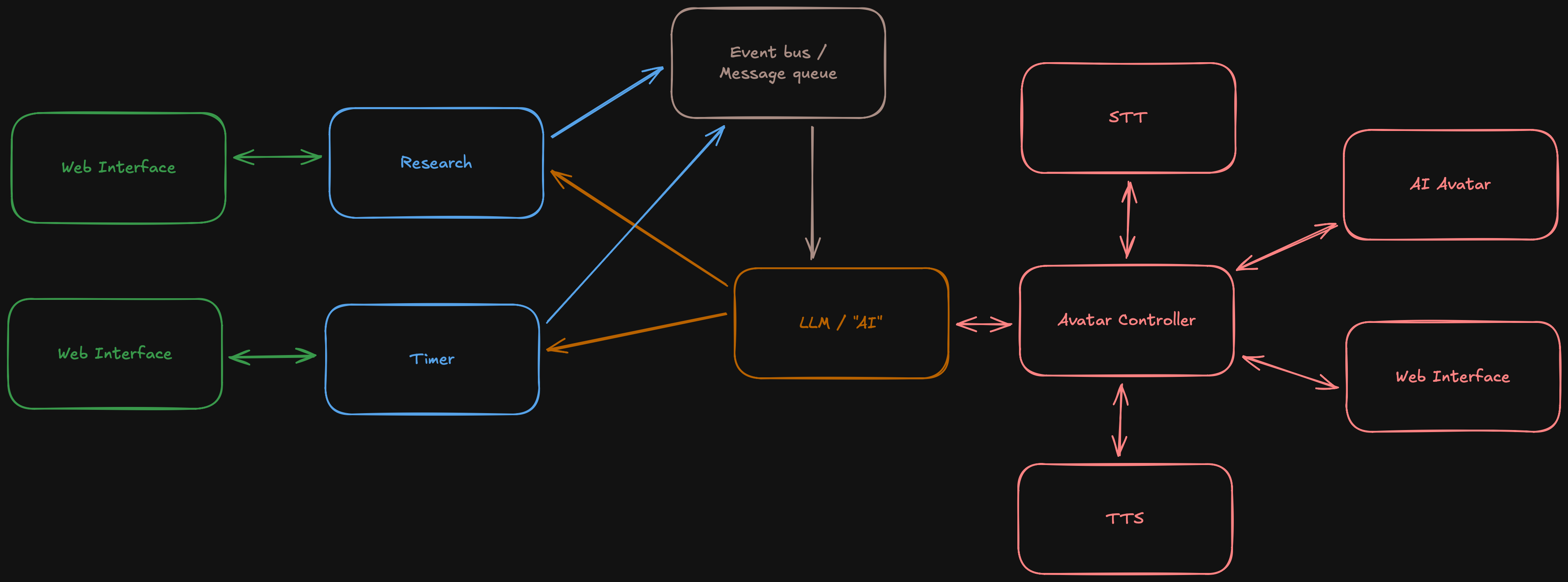
First we make message flow a bit simpler. Avatar talks to controller, controller runs STT or TTS as needed and talks to the LLM. A lot simpler as the avatar does not need to keep multiple connections going which will be nice on mobile devices.
I also dropped Delta Chat. Here is the thing, I like Delta Chat. And with PGP finger prints, DKIM and IP allow lists (my clients are always on a VPN) I would still rather keep a way to interact with most of my data off the Internet. But this also opens the opportunity to move the general web interface to the controller. I can keep state there, have the whole "chat history" in text without constantly pushing to my mobile and potentially do STT / TTS via the web interface as well.
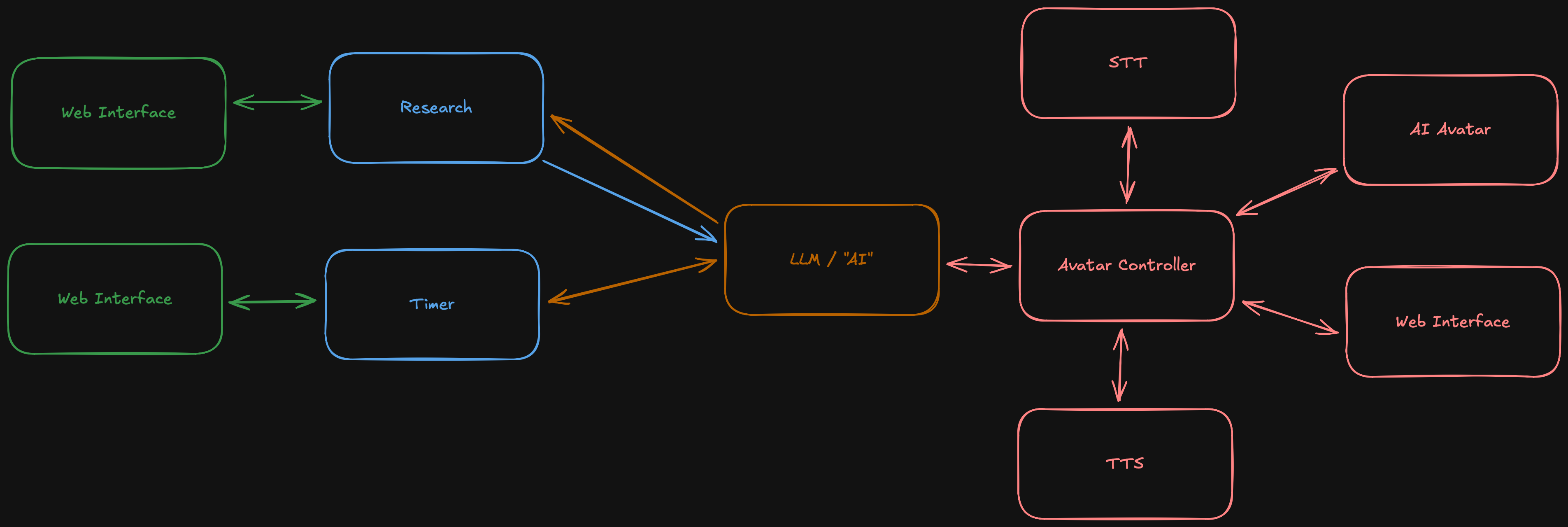
One thing I should include in the - for now - final diagram is that there might be services that do not use the event bus at all, but immediately return a result to the LLM. The timer example is a bad one, but it shows the thought process. It might actually be worth implementing MCP for some of the services.
Realistically the message bus can be an in process buffer or queue. I was toying around with the idea of fanning out to multiple consumers, but with the avatar controller taking on a bigger role and with Delta chat dropped there is no real need for it right now.
A good plan, isn't it?
Now this was a bit different than usual, but I hope for some of you this helps to see how I think through larger architectures as I approach them. Just keep in mind that nothing is set in stone. When I start working on Lazerbunny and I notice that it would be more practical to publish all messages to an event bus and consume them the diagrams will be updated.
As a rule of thumb I would suggest try to keep the number of arrows between services to a minimum. Everything talking to everything in existence means you are building a distributed monolith, not a service based architecture. And debugging will be a nightmare, believe me, I have been there.
Progress
So far I made some progress learning Blender, even though I had to start over. The good news is that the second attempt seems far more promising - things seem to be going more according to the tutorial. I also have a friend who studied this stuff and thankfully helps me with questions like "why did this thing invent edges and how do I make them go away?!". On top of that Gemini was surprisingly helpful for figuring out changes to the user interface between the tutorial and v5 and answering some beginner questions.
On the LLM front I am mostly looking at qwen3-asr, qwen3-tts and LFM. The plan is to run the avatar plus controller, stt, tts and LLM on an M2 MacMini. Resources should be fine, the stack should be realtime and LFM seems capable enough to figure out which tools and agents to delegate the work to. Those agents can then start warming the basement by running larger models if needed.
posted on Feb. 15, 2026, 10:18 p.m. in AI, lazerbunny, software engineering