So much inference, so few GPUs
Building out a small fleet of coding and research agents for LazerBunny means I regularly have requests to LLMs running, which are hosted on various hardware in my local network. This is not a big deal most of the time, but things get a little bit more interesting when multiple agents compete for the limited local resources. I spent some time this week to look into potential solutions.
There are some I ruled out:
- Buy more hardware. This has to wait till we hear "the big pop".
- Use online hosted models.
- Anything that does 400 other things I do not want.
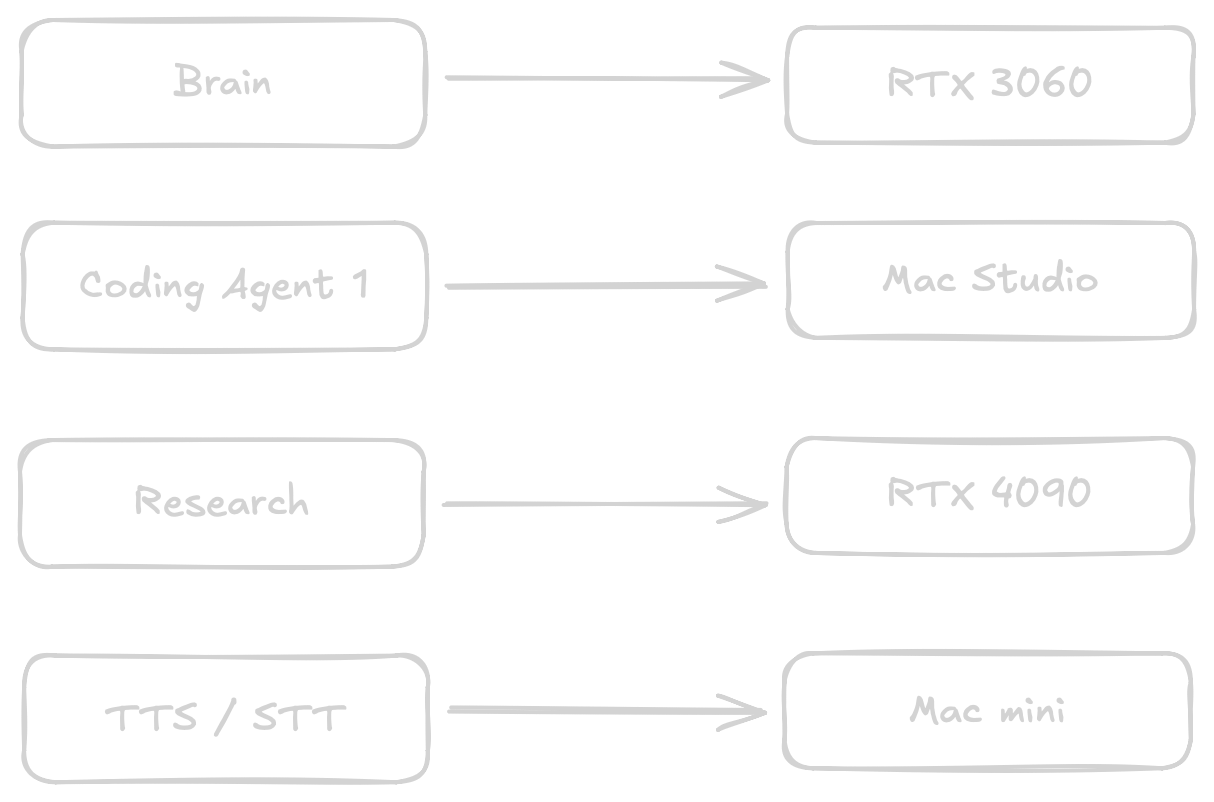
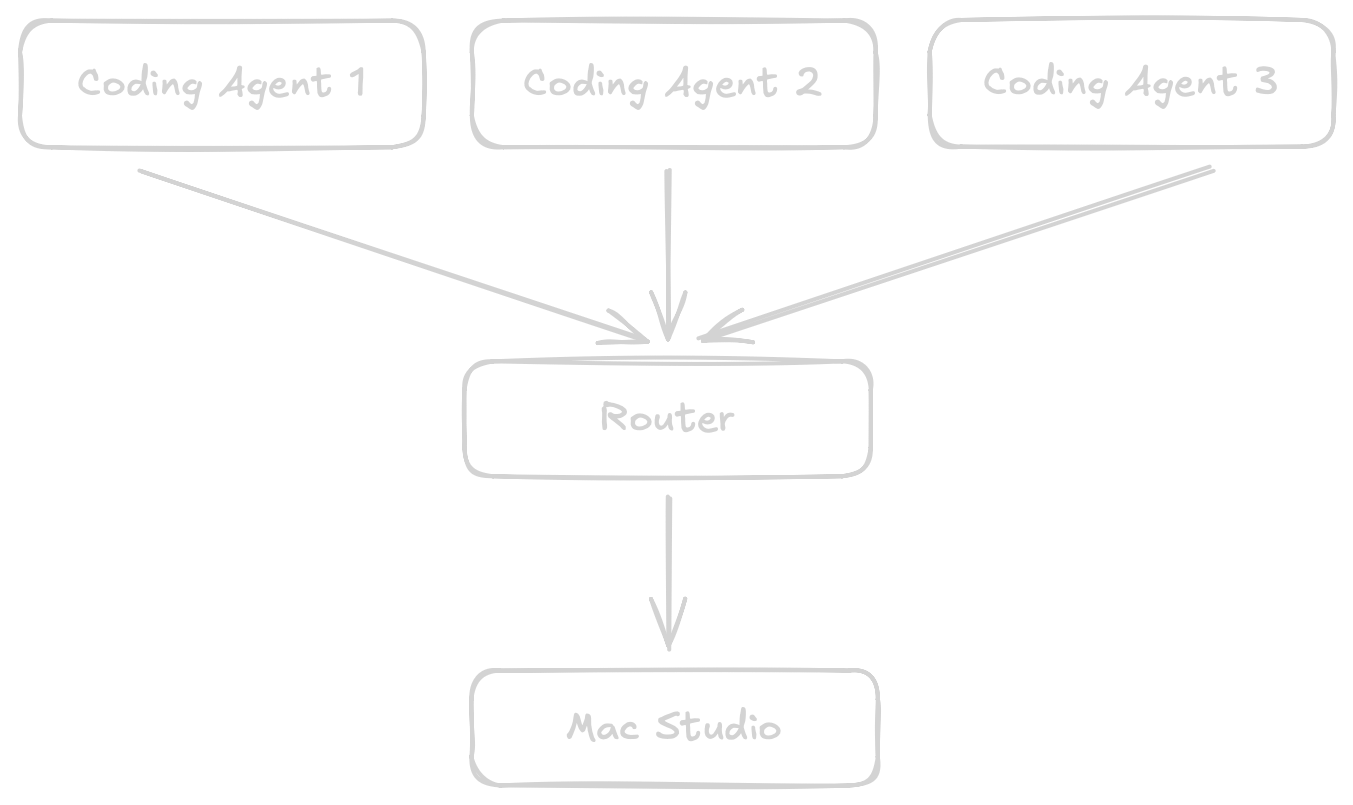
Returning to my earlier point: With only one agent per GPU things are really easy. But what if I want to have two or three coding agents running? My usual workflow is shoot off a bunch of questions or tasks to plan, make code suggestions and when I come back to the office start integrating the solutions. My agents usually do not directly edit the code, except for very small, localised changes. I prefer to take the code and manually fit it into the overall architecture.
Good, but not quiet there
I landed on a router accepting requests and not setting any timeouts. And it doesn’t seem to be the worst idea I’ve had so far. Go is pretty good at handling HTTP connections, the standard library simply runs goroutines. Add in a mutex and we are basically there. I knew one day it will pay off (beside initial debugging) having built out the OpenAI API client instead of using a library. Most of the router is re-use. (To be fair this is also something some applications providing an inference API offer out of the box.)
But this feels a bit lazy. What about research agents? What about the brain or TTS / STT? For the last two they will keep their dedicated resources. TTS / STT runs locally on a Mac mini. With 16GB memory not really a powerhouse to begin with and latency matters a lot. I do not want the resources tied up. Same goes for the brain.
I usually boot the ML system with the 4090 as needed via WoL. The Mac Studio is running while I am working, but neither machine works unsupervised through the night. (I still have to see any value in producing 10000 lines of code over night that can barely be reviewed and do not meet any quality standards.) So when the Mac Studio is running maybe the research agents could leverage a Qwen 122b MoE instead of the a 32b quant?
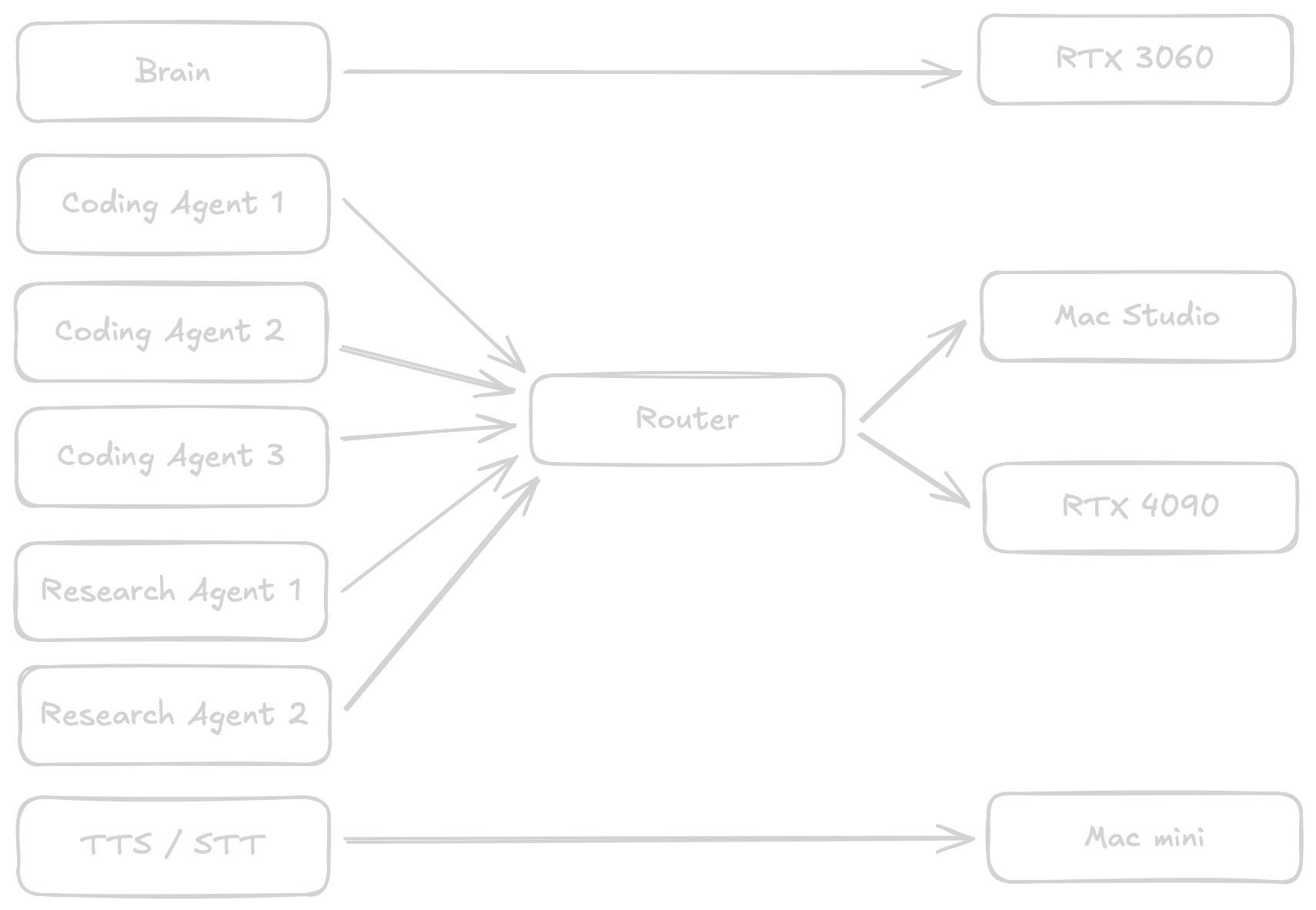
All of this means making the router a lot smarter this week. Here is the rough game plan and todo list:
- Add support for multiple LLMs, including health checks to see which host is available.
- Add properties to the request to know if a request has "priority" (I am actively working on something), a "preferred" or "required" host
- Have an actual priority queue so "priority" requests can jump ahead while the rest waits patiently.
- Be smart about routing and the last used model so one host does not play model ping-pong while another is idle.
Ping-Pong
The ping-pong part is particularly interesting for the research agent. Once data is collected via RAG, searching the web and pulling in documentation, the agents create summaries with citations from the individual documents. Once done a single agent assembles the research output. Next step is a different model critiquing the findings and asking follow up questions and weighting the relevance. A few rounds later the "judge" is either satisfied or there is a hard stop at 10 rounds and I will manually kick off a follow up task. All of this actually works fine with even 9b models.
I have seen people swap models mid coding, but have not seen a significant enough improvement switching between Qwen 3.5 and Gemma 4 for example. Other combinations I tried also did not add a lot, so model swapping is currently only in use for research.
I was considering callbacks instead of keeping the connection open but this feels unnecessarily complex compared to setting infinite timeouts and having a context for cancellation if an agent closes the connection.
Progress
Endirillia is getting hands and feet! This is exciting, as the body will be complete and I can look forward to a 5 hour tutorial on how to do hair. I wish this would be the last part, but there are 9 more steps, including getting her something to wear. Cannot have my assistant naked on a 40" TV in the background all day.
Beside that, I decided to learn a bit about traditional drawing, composition, how the flesh bags wrapped around our skeleton works and so on. I am getting further and further out of my comfort zone. It was a slow week on the technical front as most of what I did was fix a few small bugs in the session compression of the brain and thinking through LLM routing and testing some existing solutions.
posted on April 19, 2026, 3:22 p.m. in AI, lazerbunny