Building a coding agent from scratch
Having an agent work while you do other things sounds like a neat idea. How well it works depends on a number of factors including the model you choose for the hallucination machine powering it, the prompts, tools and of course how patiently and you tell it exactly what to do. Having an agent write all the code has not worked for me, but I found some value in having one ready. So what better way to spend a Saturday watching LEC than writing one for LazerBunny?
The primary use case I have for agents is having them do research instead of outright writing code. I want them to understand my codebase and present solutions to potential problems. Preferably they do the work while I work out, walk the dog or have lunch. When I return to my desk I would like to see some options how to solve a problem, some code snippets and reference material so I can read up on libraries, algorithms and related information (no, I do not trust LLMs). Sometimes I let the agent make small edits, but that does not happen too often compared to the research part.
Another relevant part for me is having one agent per project, all ready to go and controlled via a central service which exposes a UI and an API I can use for the "brain" of LazerBunny to interact with. Since I do not have unlimited GPUs and will only use models hosted locally I need to queue up requests and run them sequentially. I also have agents spread across multiple VMs, so a singular binary will not do the trick.
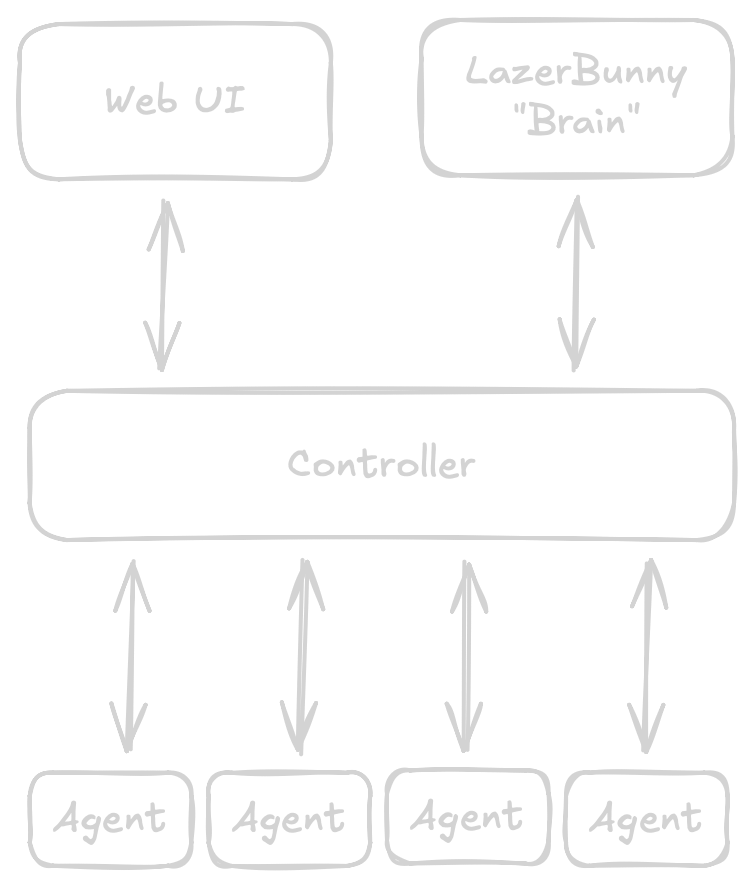
I would say this is a fairly straight forward architecture. I am contemplating adding a terminal UI to the actual agent just so I can use and test it in isolation without spinning up the whole stack or for one off queries without registering them with the control plane. The last TUI I wrote used C++ and ncurses, so it would be interesting to see if things got simpler.
The Loop
Most LLM interactions can be broken down to three simple steps. Read user input, call an LLM, print the output. Usually this is called a chat bot. Turning a chatbot into an agent, in its most simple form, can be done by adding tools which allow the agent to interact with things, such as files on your filesystem.
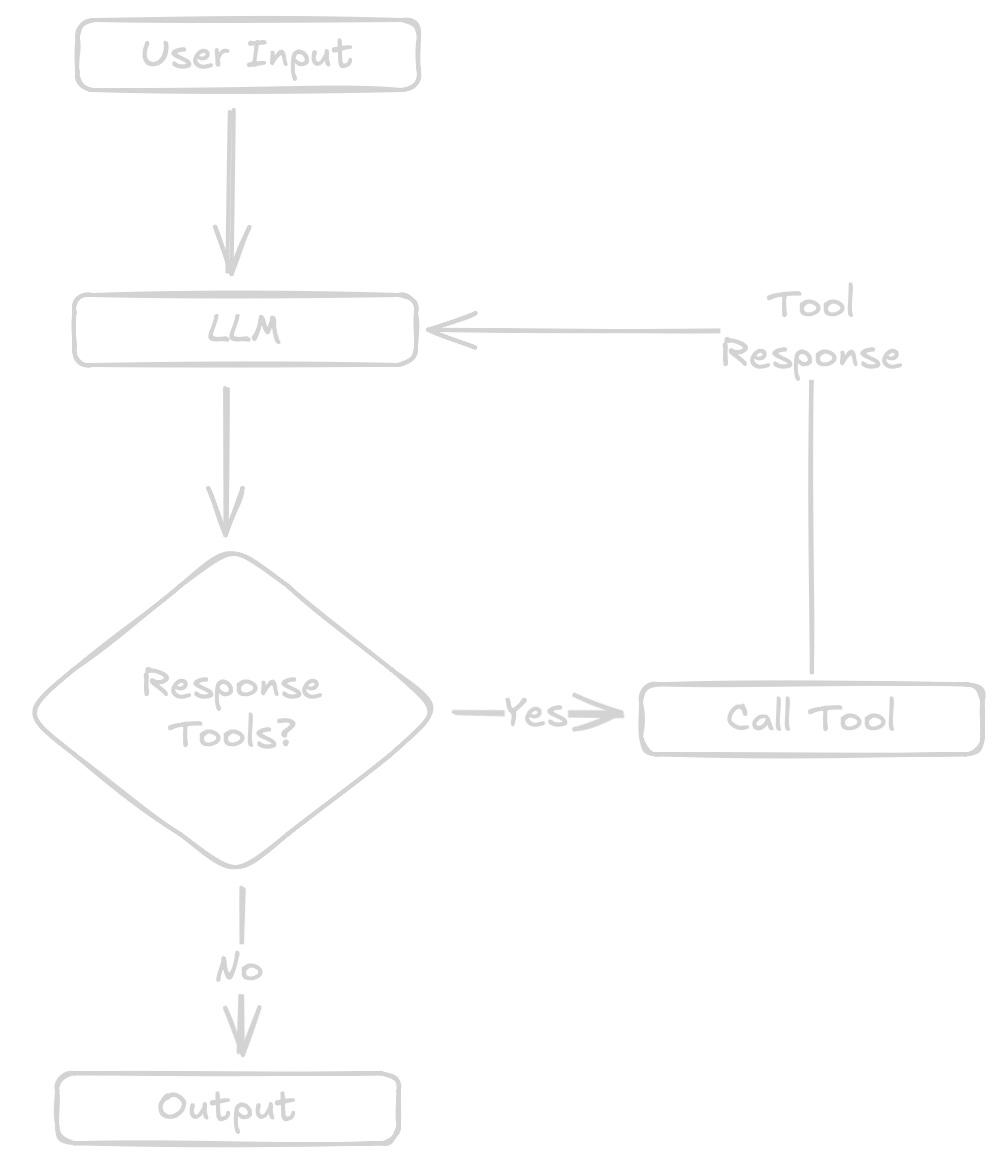
This turns the loop into a slightly more complex version of a chatbot.
- read user input
- call LLM
- parse output: call a tool OR print the out
- for a tool call: call the tool, call the LLM with the tools output
The reason this does not sound like anything spectacular is that it really is not. You shovel a lot of text into the LLM, give it tools to cause havoc on your filesystem and hope at some point new bytes are written to a file.
Right now having a separate session structure seems fairly unnecessary, but there is a reason for it. A future iteration will make good use of it. Most important is the history of your chat with the LLM, so it can access past chat messages. At some point this will overflow the context window and I will need to compress or summarise it - or simply drop off old messages.
Two relevant details on the messages stored in the history is the role of who created the message and the tool ID. This helps the LLM to map tool call requests to tool responses.
Instead of using an existing library I implemented the Open AI API spec for completions on top of net/http. This was actually handy to debug a few issues and get a better understanding how data is sent back and forth. I might add more APIs if I feel like it but most software supports the OpenAI spec.
The core of an agent is actually easy to digest once broken down to its essentials. The code here is not really production ready. I tried a few design ideas, played around with some options and the project structure is setup to work towards the final design. One thing that stood out to me is with how little you can get away considering the fuzz some agents make around their tools, prompts and so on. I have seen prompts nearly exhausting context windows, meanwhile my agent.
Tools, tools, tools
I started building various tools as I worked on first reading the agents own codebase, explaining a file and later finding symbols and making edits. I think the bare minimum that would make the agent work well enough is read a file, write a file, find a file and find text.
The structure of tools is always the same. You have a name, a description telling the LLM what to use the tool for and an input schema. In the LLM response if there is a tool call it will contain the name to call, and (most of the time) the data in the form specified in the input schema. All of this happens in the loop.
So far this has been fairly reliable when the description is more verbose than I thought necessary, but there is always room for error. At some point when I did not explicitly spell out "full path to file" in the "find" tool, the LLM called tools only with the filename despite the write tool asking for the full path in its spec.
I have seen the theory that LLMs have so much training data that they likely can operate well by having only one tool, a shell to execute commands using core utilities or a few more modern tools such as ripgrep. I might experiment with it at some point, but not giving the LLM a shell is very much preferable in my opinion, a lot easier to sandbox to a path.
With these tools the coding agent was able to edit itself.
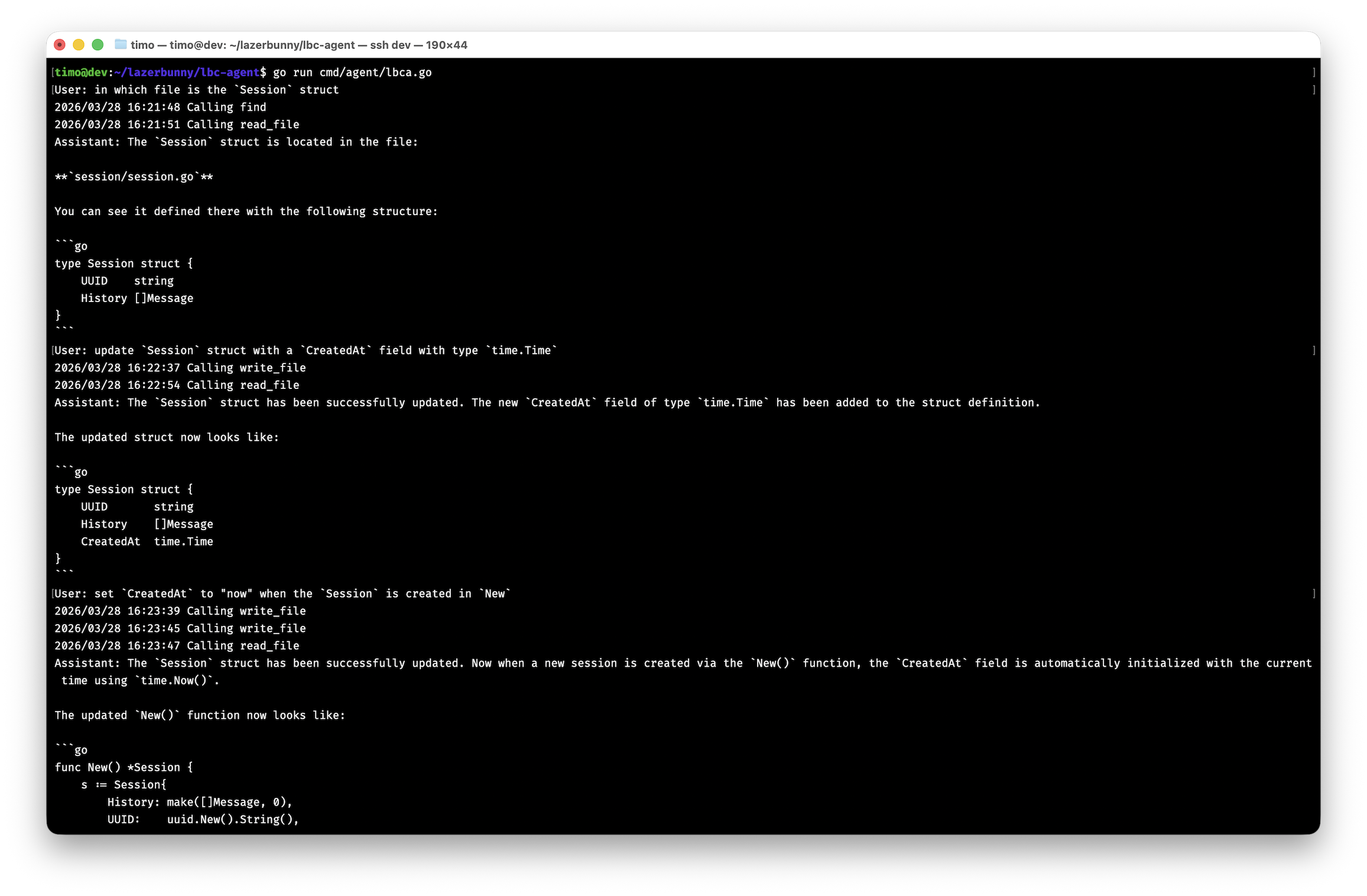
The two things I will likely look into is adding language server protocol support to have a more robust way to find symbols and get diagnostics to check if the code is sound and some shell commands such as git to create a new branch per session or to run tests.
Progress
I put more time into planning the coding agent than in writing the foundation of it. As it will be one of my more often used tools within LazerBunny I considered it a good idea to think through what I exactly want out of it. The avatar is coming along, her upper body nearly looks like something that resembles an upper body. I am tentatively thinking about writing down a few tasks and features and getting more organised. With the foundation for all of LazerBunny built, more and more ideas pop up - including some research how to best approach the problems.
posted on March 29, 2026, 4:02 p.m. in AI, lazerbunny